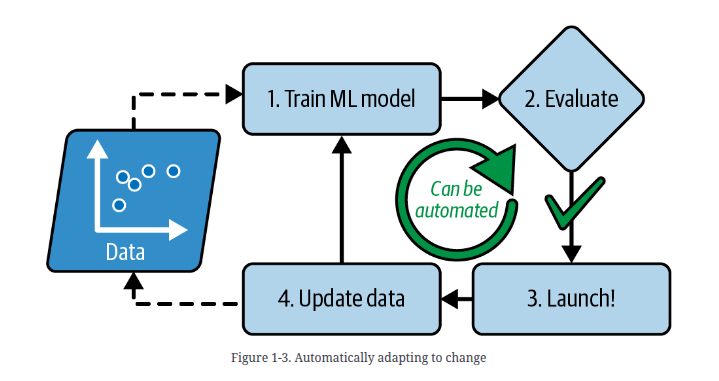
ML Series #1: an Introduction for ML beginners

That’s the beginning of my ML Series which bring me from simple regression, classification to deep learning & model deployment. Enjoy!!
Intro to ML
Recent history of ML
Although it seems that the history of ML is recent and dates from the middle of the 2010s with the rise of Big Data and the improvement of computing power.
ML has existed since the beginning of the 80s–90s, the OCR (Optical Character Recognition) technology, until then based on simple pattern matching, becomes accessible to the public (software such as OmniPage, ABBYY FineReader). At that time, algorithms begin to integrate statistical machine learning (Bayesian classifiers, k-NN, SVM) to better recognise the varied fonts.
At that time, neural networks already existed (Perceptron, backpropagation). Geoffrey Hinton and others (Yann LeCun, Bengio) worked on the subject, but the results remained limited because of the lack of data and computing power.Then in 2006, Geoffrey Hinton and his students brought neural networks back to the forefront by training a dataset of handwritten digits to predict other examples with an accuracy around 98–99%, but the real “shock” was that it worked with deeper networks, whereas before it was thought impossible to train them properly. Renaissance of Deep Learning and mainstream interest.
In 2012: real “mainstream” shift with AlexNet (Krizhevsky, Sutskever, Hinton). Thanks to GPUs and a large dataset (ImageNet), the network smashed performances in computer vision. It is from there that industry began to adopt deep learning massively.
2014–2018: explosion of applications with GANs, neural machine translation, voice assistants(Siri), then arrival of transformers (2017) which today dominate NLP and generative AI.
First mainstream ML use cases in society:
Software such as Omnipage used OCR to digitise paper documents. This began with pattern matching in the 1980s and then ended up adopting ML in the 1990s: statistical classifiers (k-NN, simple neural networks, probabilistic models) to recognise the varied fonts.
Speech recognition in the 1990s (dictation, call centres, customer service, voice commands in high-end cars).
Spam filtering (late 1990s). Deployed massively in email services (Hotmail, Yahoo Mail, later Gmail from 2004) and has replaced rule-based systems that were difficult to maintain.
Recommendation systems (late 1990s): Amazon (1998) for product recommendation.
Credit card fraud detection → banks such as Visa/Mastercard already used simple neural networks and logistic regression.
Falcon Fraud Manager from HNC Software (launched in 1993), used by Visa and Mastercard → it analysed transactions in real time with a neural network to detect anomalies.
Our First Use Case of ML: Car Price prediction
You want to sell your car but you don’t know which price is the best: you have to evaluate the market before.
What’s better than ML for helping you?
In the same way as an expert who would help you to evaluate the price of your car because he has knowledge of the market, ML will allow with the data of your car to bring out patterns and play the role of the expert by giving a price based on other cars that it has stored in memory.
For this to be possible, it is necessary to give to an ML model the characteristics of different cars, and the price of each so that it can determine a link between the two: the more it will see and the more it will train with.
When it will have seen enough cars, it will know approximately what price to give to it according to its characteristics.
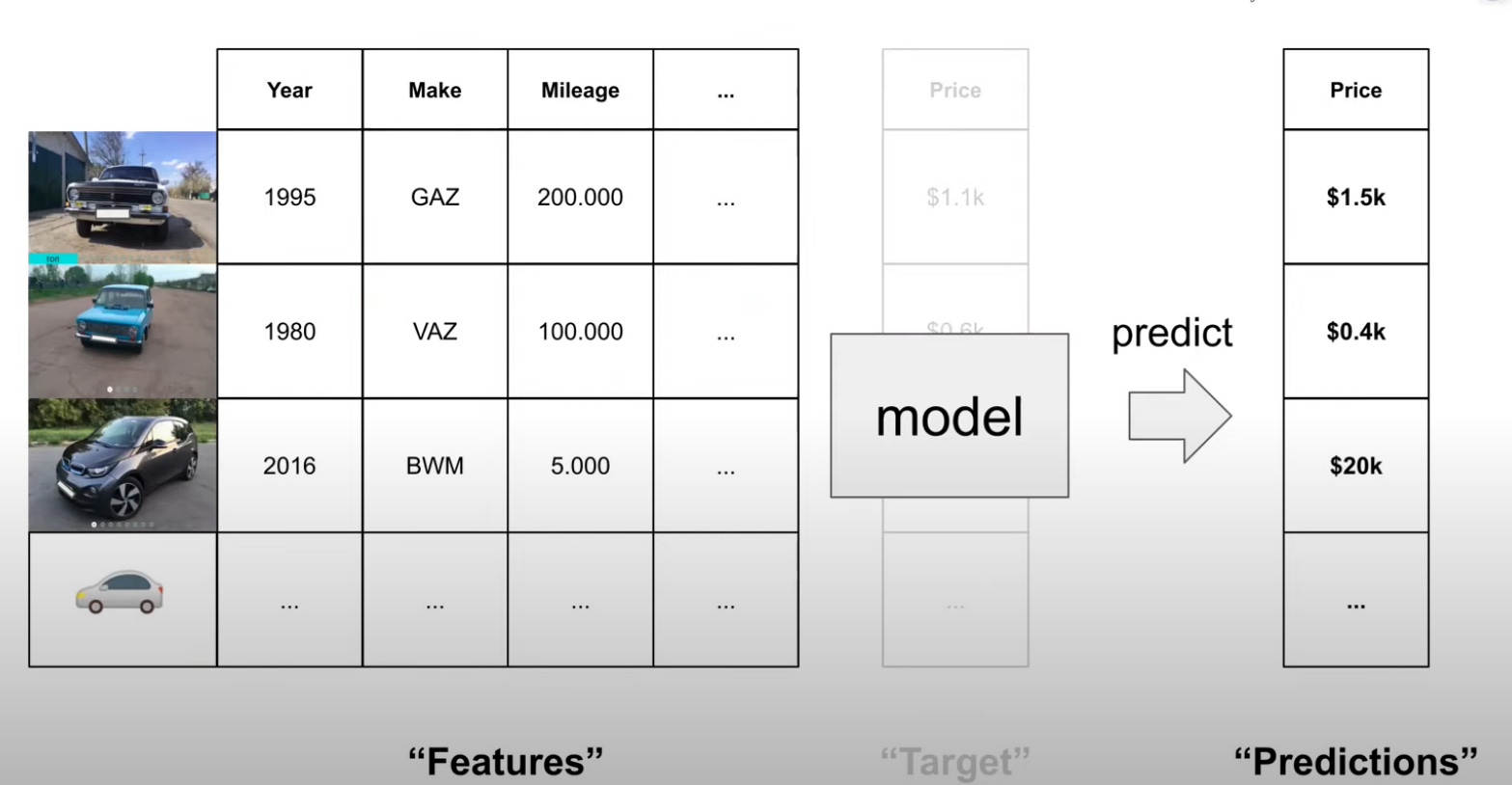
In ML language, the characteristics of the car are features, the price of the car is the target and each car present in the tabular data (the dataset) is an instance.
For each new instance with these features, the trained model will be able to give a prediction of the price.
For our use case, we can therefore propose on a website dedicated to car sales a correct price for which their car will be able to sell at a price that both they and the buyer will find acceptable.
What must be retained in general: ML is capable of extracting patterns coming from the data and the chosen ML model encapsulates these patterns through the training of different instances.
Comparison between ML & Python class objects :
Tabular data in ML:

Each row is an instance.
Its characteristics are features and can be put under a matrix form.
In linear regression terms, features are explicative variables.
Python class objects:
class Car:
def __init__(self, year, make, mileage, fuel, price):
self.year = year
self.make = make
self.mileage = mileage
self.fuel = fuel
self.price = price
c1 = Car(1995, “GAZ”, 200000, 6.5, 15000)
c2 = Car(1980, “VAZ”, 100000, 7.8, 22000)To make the parallel with the features of the matrix and tabular data, here the characteristics are the attributes of the Car class.
And c1 and c2 are also instances of the Car class and have arguments that differentiate them and occupy a different memory space.
Why ML spam-filters have replaced Rule-based systems?
For the rule-based system which is in fact a programme, the developer will notice that the spams have certain similar patterns such as:
words in the title
patterns in the sender’s name, the email’s body, and other parts of the email.
He will therefore write rules, always more rules as he receives emails.
The problem is that the spammers will adapt, seeing that their target is not reached, and change rules in their emails.
The programmer will therefore also act in reaction and write other rules and his programme will end up becoming unmaintainable and will above all become the slave for life of his rule-based system like Sisyphus pushing his rock in the underworld.

For ML spam filters you will be able to transform all the rules into a binary feature (True:False or 0/1). This is called one-hot encoding.
For each email we will be able to obtain a vector that defines it with binary features:
title length > 10? (True or False) (0/1)
body length > 10? (True or False) (0/1)
description contains “deposit”? (True or False) (0/1)
For example, an email that meets these three rules will have a vector [1,1,1] in a tabular dataset.
Then for all the emails we can build a dataset based on our features:
This can be:
conditions on the title, the body, the signature
words
combinations of words
a mixture of everything
For the target it will be quite simply whether the user pressed “SPAM” or not to determine this email (binary as well).
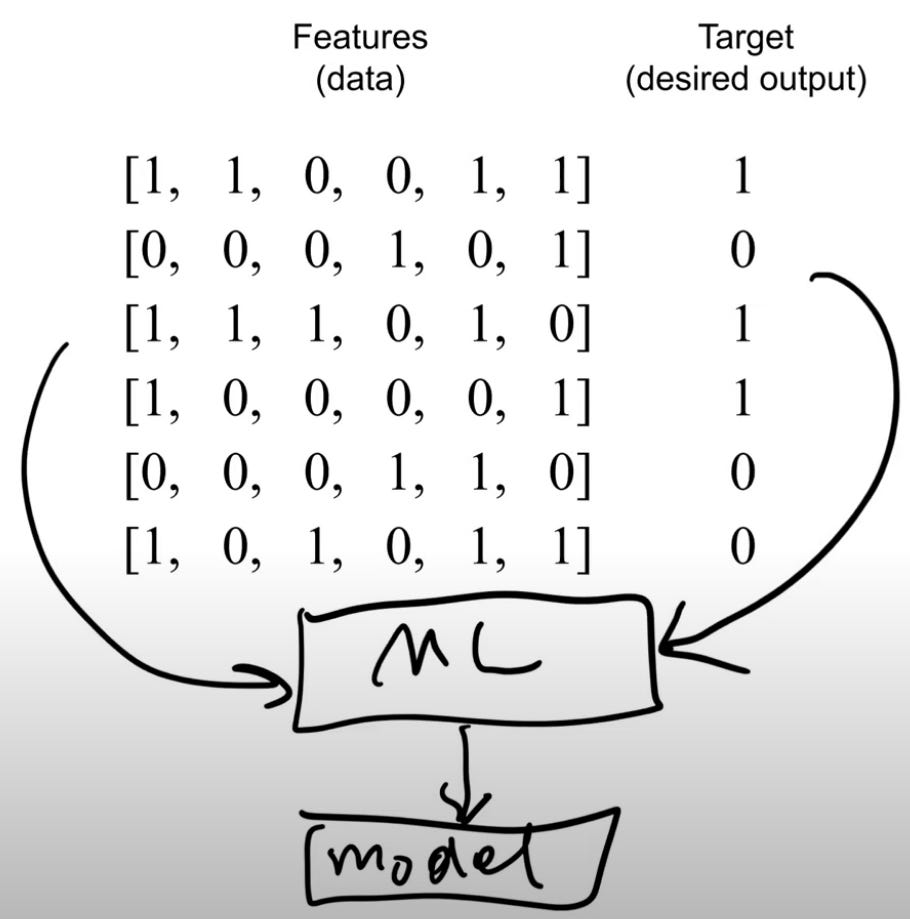
The model can be trained on all our email instances and the target.

With New instances , the model tempt to predict if it’s spam or not with a number between 0 and 1.
We define a threshold ≥ 0.5 to determine a spam email instance.
Conclusion :
It’s more practical, maintainable and more, it can be automated. You can gradually adapt your system too without more efforts.